
スクレイピングツールとは
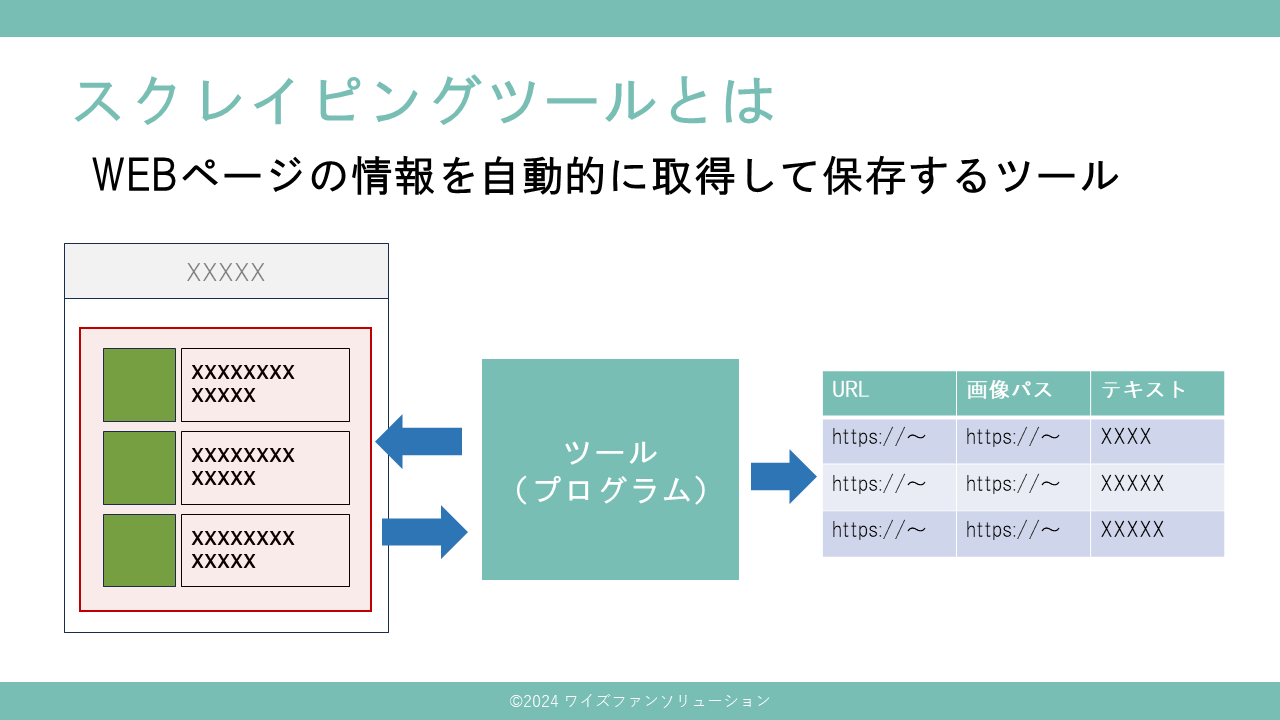
- スクレイピングツール(WEBスクレピングツールとも呼ばれる)はWEBページの情報を自動的に収集するツールです
- 例えばニュースサイトの見出し、ショッピングサイトの商品や価格などを自動的に集めてCSV形式などで保存することができます
- 1つ1つサイトにアクセスして手でコピーして貼り付ける作業を繰り返すより圧倒的に早くかつコピペミスがないので正確に情報収集できます
- バッチで定期実行すれば毎週月曜日の9時など決まったタイミングで情報を集められます
- スクレピングはサイトによっては禁止されています。サイトの利用規約を見て禁止されていないか事前にチェックしましょう
- 1つのサイトに対して短時間に大量アクセスするとサイト攻撃とみなされる可能性があります。かならずスリープを入れてサイトに負荷をかけないように配慮しましょう
スクレイピングツールを作る流れ
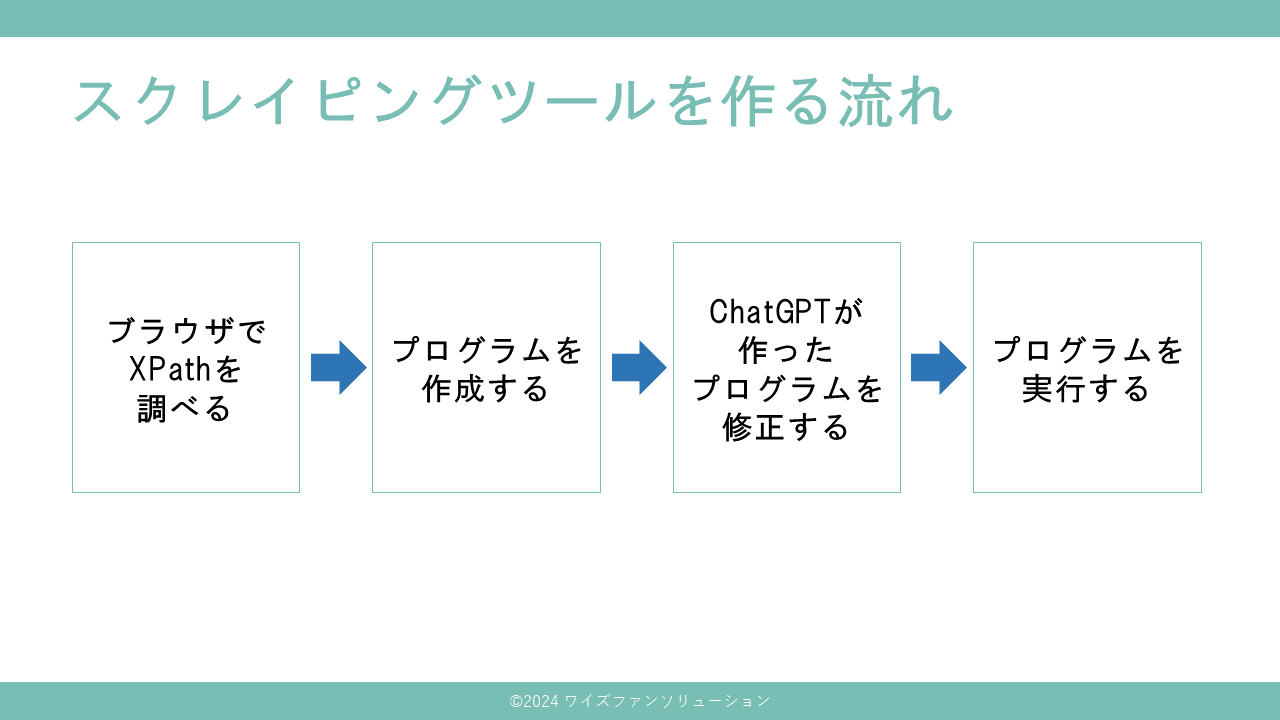
- まずブラウザで取得したい情報のXPathをコピーします
- 次にChatGPTにプロンプトを入力してプログラムを生成します
- 適宜プログラムを修正します
- プログラムを実行します
ブラウザでXPathを調べる
XPathでWEBページの特定の場所を指定することができます。コピーするだけなのでXPathとは何かという説明はここでは割愛します。例としてモジーヤの更新履歴を取得するXPathをコピーします。
Windowsを前提に説明します。まずChromeブラウザで対象ページを開き、F12ボタンを押します。取得したい要素で右クリックし、検証を押します。すると、右側のHTMLがハイライトされます。
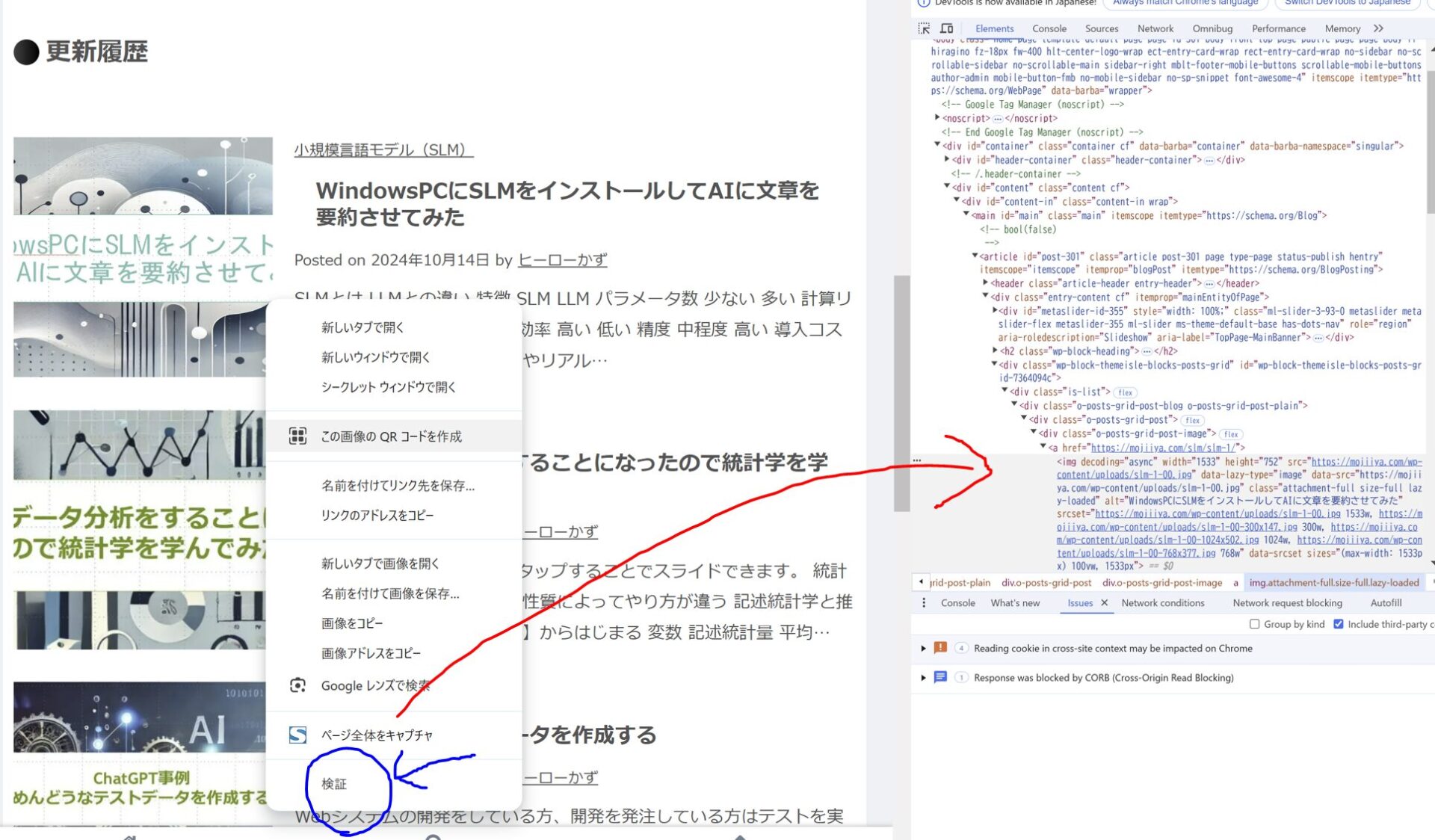
更新履歴のリストを右側のHTMLを選択し、右クリックしてからCopy full XPathをクリックします。
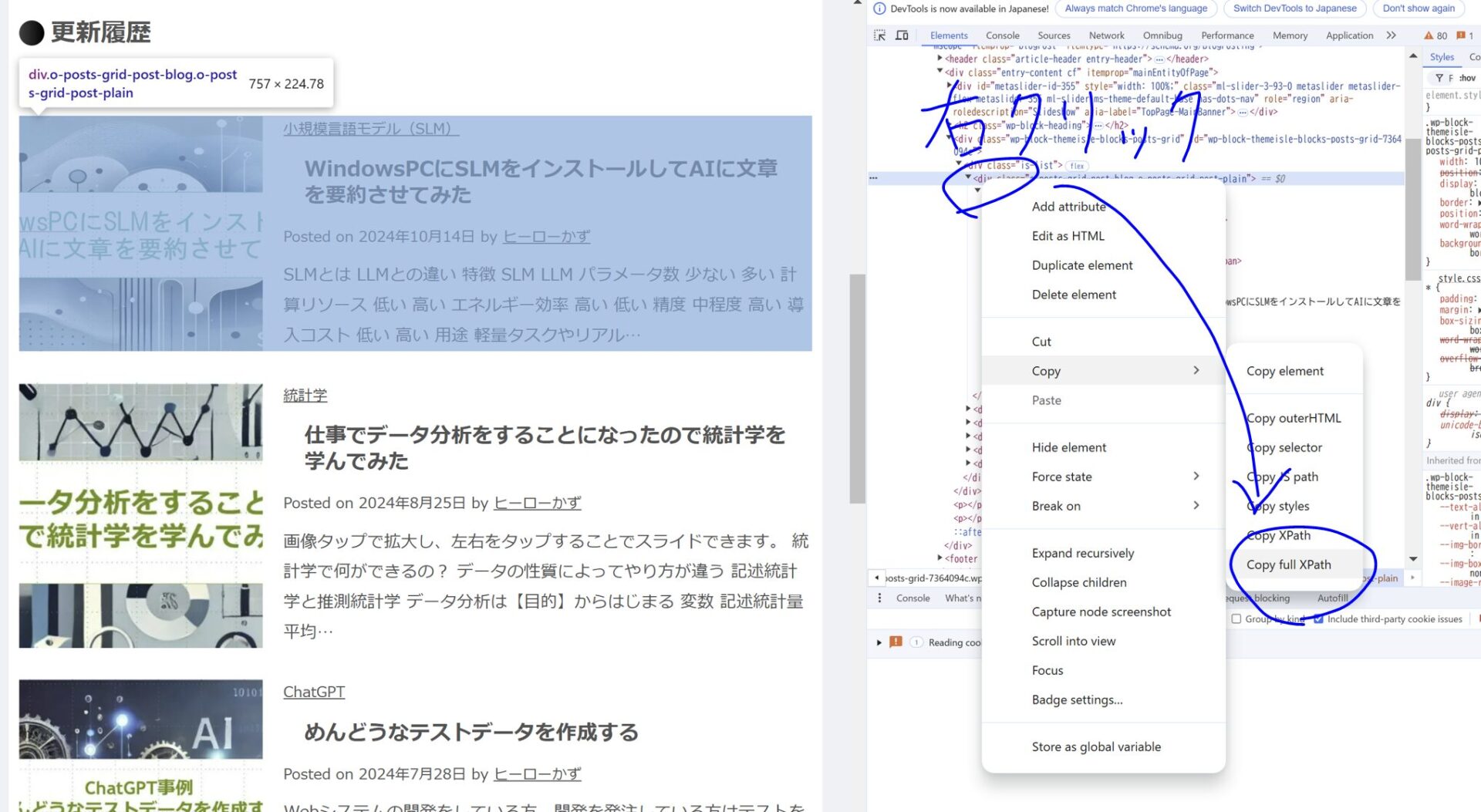
すると、次のような文字がコピーできるのでテキストエディタなどに張り付けてとっておきます。
/html/body/div[1]/div[2]/div/main/article/div/div[2]/div/div
ChatGPTでプログラムを作成する
プログラムを作成する上で有効なのはChatGPTのo1-previewです。有料ですがプログラムの精度が以前より格段に向上しています。
プロンプト例
あなたは一流のプログラマーです。私は要件に合ったプログラムの制作をあなたに依頼します。
この行いはあなたにとって重要です。集中力を切らさず真剣に取り組んでください。
まず以下の"目的"と"条件"を参照し、実装方針を検討してください。
疑問点があれば質問してください。
## 目的:
ブログサイトの更新履歴を取得し、記録する
## 条件:
- Pythonを使ってWebスクレイピングツールを実装する
- ツールはWindows PC上で実行する
- 実行時間に制限はないが、サーバーは用意できないためマシンスペックへの配慮が必要となる
- 対象ページURLのリストは"https://mojiiya.com/"
- 認証やアクセス制限はない
- スクレイピングは許可されている
- 上記URLにアクセスし、更新履歴の内容を抽出する
- 更新履歴の一覧は以下のXPathで取得できる
/html/body/div[1]/div[2]/div/main/article/div/div[2]/div/div
- 更新履歴一覧内のデータは上記XPathで取得したdiv要素配列内の下記要素から取得する
画像URL: /div/div/a/imgのsrc属性
ブログページURL: /div/div/aのhref属性
件名:/div/div/h4/aのテキスト
- 取得した結果をCSVに出力する。CSVの要素は以下の通り
取得日時
ブログページURL
件名
画像URL
- 出力するCSVはUTF-8でエンコードする
- CSVファイルの保存場所はプログラムと同じ場所にしてください。ファイル名には日時を含めてscraping_result_YYYYMMDDHHMISS.csvとしてください
こちらがChatGPTが作成したプログラムです。これをC:\workspace\scrapingにscraping.pyというファイル名で保存します。
import requests
from lxml import html
import csv
from datetime import datetime
import os
# 対象ページのURL
url = 'https://mojiiya.com/'
# ウェブページを取得
response = requests.get(url)
response.encoding = 'utf-8' # エンコーディングをUTF-8に設定
# HTMLをパース
tree = html.fromstring(response.content)
# 更新履歴のXPath
updates_xpath = '/html/body/div[1]/div[2]/div/main/article/div/div[2]/div/div'
# 更新履歴の要素を取得
updates = tree.xpath(updates_xpath)
# 現在の日時を取得
current_datetime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# データを格納するリスト
data_list = []
# 各更新履歴からデータを抽出
for update in updates:
# 画像URL
image_url = update.xpath('.//div/div/a/img/@src')
image_url = image_url[0] if image_url else ''
# ブログページURL
blog_page_url = update.xpath('.//div/div/a/@href')
blog_page_url = blog_page_url[0] if blog_page_url else ''
# 件名
subject = update.xpath('.//div/div/h4/a/text()')
subject = subject[0] if subject else ''
# データをリストに追加
data_list.append([current_datetime, blog_page_url, subject, image_url])
# CSVファイル名を作成
csv_filename = 'scraping_result_{}.csv'.format(datetime.now().strftime('%Y%m%d%H%M%S'))
# CSVファイルを保存
with open(csv_filename, 'w', newline='', encoding='utf-8') as csvfile:
csvwriter = csv.writer(csvfile)
# ヘッダーを書き込み
csvwriter.writerow(['取得日時', 'ブログページURL', '件名', '画像URL'])
# データを書き込み
csvwriter.writerows(data_list)
print('データの取得とCSVへの保存が完了しました。ファイル名: {}'.format(csv_filename))
ChatGPTが作成したプログラムを修正する
今回はたまたま修正箇所がありませんでした。おかしい箇所があった場合、ChatGPTに指示することで修正してくれます。
プログラムを実行する
実行するにはPythonをインストールする必要があります。インストール方法はこちらに記載がありますので参考にしてください。実行にはPythonのライブラリも必要になりますが、そのインストール方法は以下のようにChatGPTが教えてくれます。

では、実際に動かしてみます。スタートボタンを押してcmdと入力し、コマンドプロンプトをクリックします。

そこで以下のコマンドを入力します。
cd c:\workspace\scraping
python scraping.py成功すると、以下のように表示されます。

実際にCSVファイルを開くと、更新履歴が保存されています。

まとめ
物販や競合分析を行っている方は定期的にサイトを訪問し、コピペで情報を記録するのはかなりたいへんだと思います。スクレイピングツールは高額なので、無料で手軽に作成できるこの方法はかなり便利です。当ページに掲載しましたプロンプトを変えることで下記のようなことも可能になります。
- URLをテキストファイルから読み込むようにすることで複数のURLに一気にアクセスできるようにする ※負荷軽減のためにスリープを入れるようにChatGPTに指示してください
- XPathをURLごとに設定できるようにCSVファイルを読み込むよう変更する
- 通常価格、値引き価格など価格表記が統一されていないサイトに対応するためにHTML形式で取得する
また、この方法を応用することで自社や他社サイトのSEO対策状況を把握することも可能です。そちらについては別の機会に投稿しようと思います。
